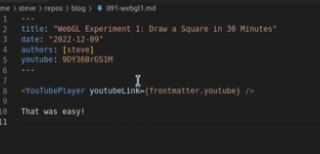
포스트 메인
- https://www.youtube.com/watch?v=rB1uyE7tJKw&list=PL3Kz_hCNpKSQ5gDVSWvrQ-9COk0CLLrTs
패키지 설치
-
패키지 2개 설치
-
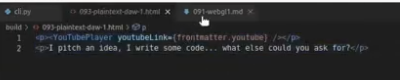
frontmatter: md render시 무시되는 front matter data를 파싱하기 위해서poetry add frontmatter
-
markdown: md를 html로 렌더링- 패키지잇슈로 3.11.6 버전에서 poetry add가 안됨.
-
pip install markdown -
-
그냥 venv -> pip install로 2개 설치함.
.\.venv\Scripts\activate
pip install frontmatter markdown
-
markdown.markdown(' 마크다운# 등의 텍스트 ')를 print하면 html로 나온다.
#이h1태그로 바껴서 나온다.
```python import markdown
if name == 'main': import markdown print(markdown.markdown('#Hellow markdown'))
Hellow markdown
```
cli를 사용할 수 있게 setup.py(name이 cli명령어)
- http://stackoverflow.com/questions/56534678/how-to-create-a-cli-in-python-that-can-be-installed-with-pip

-
루트에 setup.py 생성
- 핵심은 entry_points안에 console_scripts 내부에
name = 패키지명(폴더/init).패키지내실행py파일명:내부함수명을 넣어주는 것 같다. - 추후
name이cli명령어가 되므로 짧게 짓는다..
```python from distutils.core import setup
setup( name='mdr', version='1.0.0', description='Markdown Renderer', author='JaeSeong Cho', author_email='tingstyle1@gmail.com', packages=['markdown_renderer'], entry_points={ 'console_scripts': [ 'mdr = markdown_renderer.cli:cli_entry_point' ], }, install_requires=[ 'markdown', 'frontmatter', ], ) ```
- 핵심은 entry_points안에 console_scripts 내부에
-
명시해둔 python패키지 폴더인
markdown_renderer생성 및cli.py및내부 함수 cli_entry_point작성
python def cli_entry_point(): print('cli_entry_point') -
영상에서는 pip install -e로 올려놓고 설치하는 것 같은데
pip install setup.py를 하면 cli가 작동하게 된다.shell (.venv) PS C:\Users\cho_desktop\PycharmProjects\markdown> mdr cli_entry_point -
이제 함수작성 때마다
pip install setup.py를 해줘야하므로, 일단 내용부터 작성하여 내부실행시키자.```python def cli_entry_point(): print('cli_entry_point22')
if name == 'main': cli_entry_point() ```
cli setup해서 사용전 cli_entry_point 함수 내용 작성
-
md들이 있는 폴더가 존재해야한다
```python import os.path
def cli_entry_point(): SOURCE_DIR = '../docs' OUTPUT_DIR = '../html'
# 1) source폴더명이 존재하고 && 그게 진짜 디렉토리라면, if os.path.exists(SOURCE_DIR) and os.path.isdir(SOURCE_DIR): ... else: print(f"'{SOURCE_DIR}' 폴더가 존재하지 않습니다.")if name == 'main': cli_entry_point() ```
-
내부 폴더 및 파일들을
os.walk()로 가져온다```python
1) source폴더명이 존재하고 && 그게 진짜 디렉토리라면,
if os.path.exists(SOURCE_DIR) and os.path.isdir(SOURCE_DIR): # 2) os.walk로 root, 내부dirs, files를 가져온다. for root, inner_dirs, files in os.walk(SOURCE_DIR): # 3) root를 출력한다. print(root) # 4) dirs를 출력한다. print(inner_dirs) # 5) files를 출력한다. print(files) ```
-
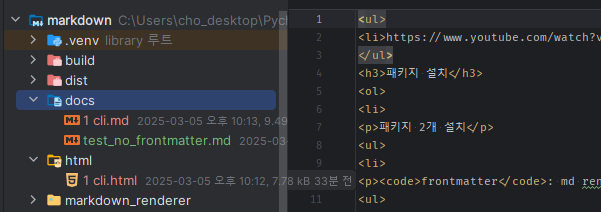
파일중에 .md로 끝내는 것들만 root + 파일이름을 가져온다.
```python files_to_render = []
2) os.walk로 root, 내부dirs, files를 가져온다.
for root, inner_dirs, files in os.walk(SOURCE_DIR): # print(root) # ../docs # print(inner_dirs) # print(files) # [] # ['1 cli.md']
for filename in files: # 3) 파일명이 .md로 끝나는지 확인하고 그렇다면, root + filename을 합쳐서 파일 경로를 저장한다. if filename.lower().endswith('.md'): files_to_render.append(os.path.join(root, filename))print(files_to_render) # ['../docs\1 cli.md']
```
-
버전차이로 frontmatter.load()는 안되서, f.read() -> frontmatter.FrontMatter.read()로 읽어서 확인해봤음.
- 문제는
frontmatter가 없으면 아예 body도 None
```python
4) 랜더할 md file들을 순회하면서, frontmatter를 뽑아내고, markdown으로 변환한다.
for file_to_render in files_to_render: with open(file_to_render, 'r', encoding='utf-8') as f: content = f.read() # c = frontmatter.loads(content) # 버전 차이? post = frontmatter.Frontmatter.read(content) print(post) # {'attributes': None, 'body': '', 'frontmatter': ''} # => md파일에 ---로 프론트매터를 넣고 나면 # { # 'attributes': {'title': '넣었다'}, # 'body': '- https://www.youtube.com/wat', # 'frontmatter': "\ntitle: '넣었다'\n" # } ```
- frontmatter가 없으면 일단은 pass하도록 한다.
```python
4) 랜더할 md file들을 순회하면서, frontmatter를 뽑아내고, markdown으로 변환한다.
for file_to_render in files_to_render: with open(file_to_render, 'r', encoding='utf-8') as f: content = f.read() # c = frontmatter.loads(content) # 버전 차이? post = frontmatter.Frontmatter.read(content) if not post['attributes']: # {'attributes': None, 'body': '', 'frontmatter': ''} print(f'frontmatter가 없는 파일: {file_to_render}') continue else: # { # 'attributes': {'title': '넣었다'}, # 'body': '- https://www.youtube.com/wat', # 'frontmatter': "\ntitle: '넣었다'\n" # } print(f"frontmatter: {post['attributes']}") print(f"body: {post['body'][:10]}")```
- 문제는
-
frontmatter를 가진 post객체에서 body만 markdown.markdown으로 랜더링한 뒤, html파일로 쓴다.
- 이 때, 상대경로 유지중이며, join시 문제가 생겨, OUTPUT_DIR을 SOURCE_DIR로 대체하도록 html파일명을 생성한다.
```python
4) 랜더할 md file들을 순회하면서, frontmatter를 뽑아내고, markdown으로 변환한다.
for file_to_render in files_to_render: with open(file_to_render, 'r', encoding='utf-8') as f: content = f.read() # c = frontmatter.loads(content) # 버전 차이? post = frontmatter.Frontmatter.read(content)
# 5) frontmatter없는 파일은 pass if not post['attributes']: # {'attributes': None, 'body': '', 'frontmatter': ''} print(f'frontmatter가 없는 파일: {file_to_render}') continue # { # 'attributes': {'title': '넣었다'}, # 'body': '- https://www.youtube.com/wat', # 'frontmatter': "\ntitle: '넣었다'\n" # } # 6) frontmatter가 있는 파일은, markdown으로 변환후 html로 써서 저장한다. html = markdown.markdown(post['body']) # 7) md파일 경로 그대로, html로 바꿔서 저장 # -> OUTPUT_DIRSOURCE_DIR을 공백으로 대체 제거 + md를 html로 교체 2번 replace # output_file = os.path.join(OUTPUT_DIR, file_to_render.replace(SOURCE_DIR, '').replace('.md', '.html')) output_file = os.path.join(file_to_render.replace(SOURCE_DIR, OUTPUT_DIR).replace('.md', '.html')) # 8) 파일경로 + os.path.dirname() 경로를 만들어준다. os.makedirs(os.path.dirname(output_file), exist_ok=True) # 9) html로 변환된 내용을 파일에 쓴다. with open(output_file, 'w', encoding='utf-8') as f: f.write(html)```
.renderignore파일을 만들어서, 거기포함된 것은 render목록에서 제외시키기
-
source_dir인
../docs에.renderignore파일을 만든다. -
os.walk로 순회하기 전에, source_dir에 ignore파일이 존재하면, 거기에 있는 파일명을 모아둔다.
```python
1) source폴더명이 존재하고 && 그게 진짜 디렉토리라면,
if os.path.exists(SOURCE_DIR) and os.path.isdir(SOURCE_DIR):
files_to_render = [] files_to_render_ignore = [] # 10) SOURCE_DIR에 .renderignore 파일이 존재하면 읽어서 모아둔다. render_ignore = os.path.join(SOURCE_DIR, '.renderignore') if os.path.exists(render_ignore): with open(render_ignore, 'r', encoding='utf-8') as f: files_to_render_ignore = f.read().split('\n') # 2) os.walk로 root, 내부dirs, files를 가져온다. for root, inner_dirs, files in os.walk(SOURCE_DIR):```
-
os.walk중에는 files단위로 나오니까, 개별파일을 md파일인지 확인하여 append하기 전에, renderignore에 포함되면 무시한다.
-
코드 리팩토링 들어감
-
조건 2개
- .renderignore파일 pass
- md파일도 아니고 renderignore도 아니라면 pass
- md파일이라도 renderignore에 포함되면 pass
```python
2) os.walk로 root, 내부dirs, files를 가져온다.
for root, inner_dirs, file_names in os.walk(SOURCE_DIR):
# print(root) # ../docs # print(inner_dirs) # print(file_names) # [] # ['1 cli.md'] # 11) md파일인지 확인하기 전에 # append될 file(상대경로)과, file의 맨 끝 파일명 file_basename을 이용하여 검사 for file_name in file_names: file = os.path.join(root, file_name) file_basename = os.path.basename(file) # 11-1) renderignore 파일이면 pass if file_basename == '.renderignore': continue # 11-2) md파일도 아니면서 .renderignore도 아닌 것 -> pass if not file_basename.lower().endswith('.md'): print(f' SOURCE_DIR 폴더에 md파일이 아닌 것이 존재 >> {file_basename}') continue # 11-3) 파일명이 .renderignore에 포함되어 있다면, pass if file_basename in files_to_render_ignore: print(f" 제외된 파일 목록 >> {file_basename}") continue # 3) 파일명이 .md로 끝나는지 확인하고 그렇다면, root + filename을 합쳐서 파일 경로를 저장한다. # if filename.lower().endswith('.md'): files_to_render.append(file) print(f"files_to_render >> {files_to_render}")```
-
jinja2 도입 - render하면서 frontmatter정보도 변수로 넘길 수 있다?!
-
설치 및 setup.py에 추가하기
shell (.venv) PS C:\Users\cho_desktop\PycharmProjects\markdown> pip install jinja2```python from distutils.core import setup
setup( name='mdr', version='1.0.0', description='Markdown Renderer', author='JaeSeong Cho', author_email='tingstyle1@gmail.com', packages=['markdown_renderer'], entry_points={ 'console_scripts': [ 'mdr = markdown_renderer.cli:cli_entry_point' ], }, install_requires=[ 'markdown', 'frontmatter', 'jinja2' ], ) ```
-
output_dir을 ../html에서 build로 변경
python def cli_entry_point(): SOURCE_DIR = '../docs' # 상대경로 # OUTPUT_DIR = '../html' # 상대경로 OUTPUT_DIR = 'build' # 상대경로- 패키지 > build폴더에 빌드된다.
-
패키지 내부 template_dir를 web으로 정하고, jinja2환경변수로 env변수에 template폴더를 지정한다.
```python
Render Logic
12) 순회하며 f.read()할텐데, 그 전에, jinja2 env파일을 만들고, env.get_template()을 이용하여 채울 템플릿을 가져온다.
env = jinja2.Environment(loader=jinja2.FileSystemLoader(TEMPLATE_DIR))
4) 랜더할 md file들을 순회하면서, frontmatter를 뽑아내고, markdown으로 변환한다.
for file_to_render in files_to_render: with open(file_to_render, 'r', encoding='utf-8') as f: content = f.read() ```
python def cli_entry_point(): SOURCE_DIR = '../docs' # 소스는 패키지 밖의 루트 폴더에서 # OUTPUT_DIR = '../html' # 상대경로 OUTPUT_DIR = 'build' # 빌드는 패키지 내부의 폴더에서 TEMPLATE_DIR = 'md_templates' # 템플릿도 패키지내부 폴더에서 제공할 것으로 지정 -
env변수에 적힌 template_dir에서 contents.html을 가져오도록 패키지내부 폴더생성, contents.html 생성을 해준다.
python env = jinja2.Environment(loader=jinja2.FileSystemLoader(TEMPLATE_DIR)) content_template = env.get_template('contents.html') -
이제 f.write()로 html을 쓰기전에, template변수.render(body=html)을 통해
한번 render된 html을 쓰게 한다.```python
9) html로 변환된 내용을 파일에 쓴다.
13) html -> template.render()한 것을 쓰도록 로직 추가
content = content_template.render(title=post['attributes']['title'], body=html) with open(output_file, 'w', encoding='utf-8') as f: f.write(content) ```
- 이대로 실행하면 1 cli.html 빌드된 것에는 아무것도 안뜬다. 왜냐면 변수로 넘긴 것을 html에서 jinja문법으로 받아서 써야하기 때문
-
이제 md_templates 폴더에
base.html을 만들고detail.html은 base.html 상속한 뒤, 내부에서 사용해보자.```html <!DOCTYPE html>
{% block content %} {% endblock %} ``` -
body=html을 변수로 받은 contents.html은 base상속 이후,
block에서{{ body }}를 사용하여 표기되게 한다.```html
{% block content %}
제목
{{ body }} {% endblock content %} ```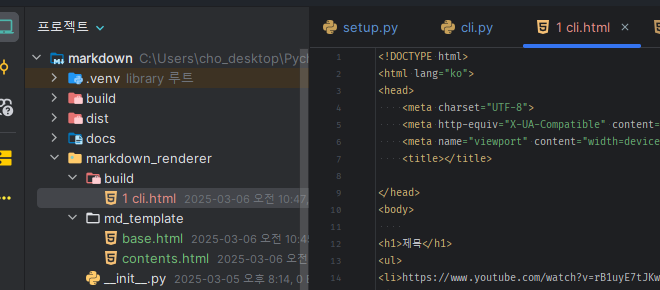
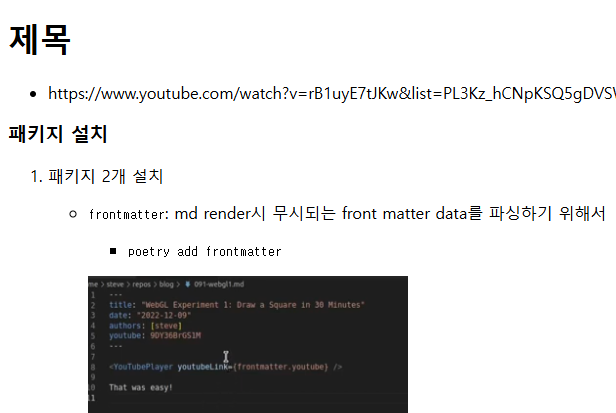
index.html 도입하기
-
개별 contents들을 render -> 쓰기 한 이후에 index는 따로다.
-
template 변수 생성
- html에는 test=, posts 보내기
```python
Render index
index_template = env.get_template('index.html') ```
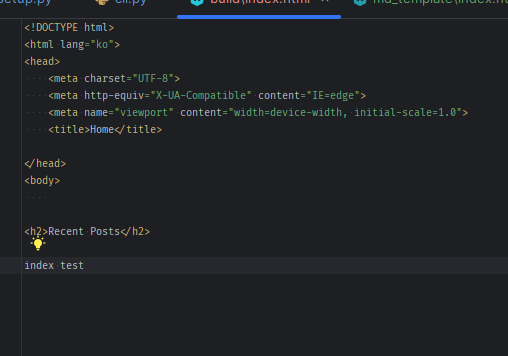
```html
{% block title %}Home{% endblock %}
{% block content %}
Recent Posts
{{ test }}
{% for post in posts[0:5] %}
{% endblock %} ```
-
개별 posts를 써야하는데 일단은 사용x
```python
Render index
index_template = env.get_template('index.html') index = index_template.render(test='index test', posts=[]) index_file = os.path.join(OUTPUT_DIR, 'index.html') with open(index_file, 'w', encoding='utf-8') as f: f.write(index) ```
manfest.in 도입 -> 패키지에 template파일도 같이 설치되게
- MANIFEST.in 파일은 파이썬 패키지에 포함시키고 싶은 파일을 담는 파일입니다. readme 파일이나 라이선스 파일과 같은 파일이 이에 해당합니다.
MANIFEST.in 파일의 용도
- 내부 패키지 디렉터리에 있지 않지만 포함시키고 싶은 파일을 담습니다.
- 소스 배포판을 만들 때 사용됩니다.
-
MANIFEST.in 파일이 없으면 기본 파일 집합만으로 매니페스트를 만듭니다.
-
root에 생성하여 recursive로 패키지에 template파일 전체를 포함시키게 한다.
recursive-include markdown_renderer/md_templates * -
setup.py에 package_data로 명시해준다.
- setuptools를 사용하진 않지만 import해주라고 한다.
```python import setuptools from distutils.core import setup
setup( name='mdr', version='1.0.0', description='Markdown Renderer', author='JaeSeong Cho', author_email='tingstyle1@gmail.com', packages=['markdown_renderer'], entry_points={ 'console_scripts': [ 'mdr = markdown_renderer.cli:cli_entry_point' ], }, install_requires=[ 'markdown', 'frontmatter', 'jinja2' ], package_data={ 'markdown_renderer': ['md_templates/*'] } ) ```
-
python setup.py bdist_wheel이나python setup.py install이나 동일한 듯하다.-
bdist_wheel로 실행하면 dist폴더가 생성되며, 내부에 wheel 파일이 생성된다.-
이건 unzip으로 맥에서 풀어야한다 나는 install로 하자
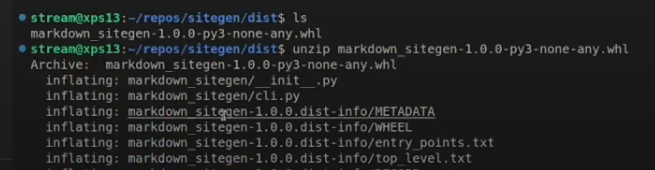
-
-
그래도 에러
``` error: [WinError 32] 다른 프로세스가 파일을 사용 중이기 때문에 프로세스가 액세스 할 수 없습니다: 'c:\users\cho_desktop\pycharmprojects\markdown\.venv\lib\site-packages \mdr-1.0.0-py3.11.egg'
```
-
mdr명령어로 해봤는데, 파일명만 뜬다?
-
리팩토링포함, posts로 전환 index처리까지
render전에 posts 라고 미리 render할 경로 검사후 모아놓기 + path속성 처리
-
os.walk로 읽은 파일의 경로 file -> full_path
-
render할 file 경로 -> files_full_path_to_render
-
패키지내 build폴더 삭제로직 먼저 하도록 추가
```python
14) build폴더 삭제 미리 해놓기
if os.path.exists(OUTPUT_DIR): shutil.rmtree(OUTPUT_DIR) ```
-
render전 post정보를 먼저 추출한다.
- path 속성이 있고, 그게 중복이 아니라면 가능
```python post_paths = {} # 모든 post에 대한 path들을 모은다. TODO: DB에서 검사
4) 랜더할 md file들을 순회하면서, frontmatter 추출
for file_full_path in files_full_path_to_render: with open(file_full_path, 'r', encoding='utf-8') as f: content = f.read() post = frontmatter.Frontmatter.read(content) # c = frontmatter.loads(content) # 버전 차이?
# 5) frontmatter없는 파일은 pass if 'attributes'not in post: # {'attributes': None, 'body': '', 'frontmatter': ''} # raise ValueError('해당파일에 frontmatter가 빠짐: ', file_full_path) print(f'🤣 frontmatter가 없는 파일 수정 요망: {file_full_path}') continue ## front용 path지정(백엔드 달리면 필요 없을 듯) # 15-1) path 속성이 있다면, 파일명이 아니라, [path].html로 상대 경로를 지정한다. if 'path' in post['attributes']: # 15-2) path는 중복이 아니여야 한다. if post['attributes']['path'] in post_paths: # raise ValueError(f'중복된 path가 있습니다: {post["path"]}') print(f'🤣 중복된 path를 가진 파일 : {file_full_path}') print(f'post_paths >> {post_paths}') continue # 15-3) 중복이 아닌 path는 True로 체크해서 추후 중복이 안되게 한다. post_paths[post['path']] = True```
- 이렇게 모은 것들을 posts라고 한다.
```python posts = [] # post_paths = {} # 모든 post에 대한 path들을 모은다. TODO: DB에서 검사 # 4) 랜더할 md file들을 순회하면서, frontmatter 추출 for file_full_path in files_full_path_to_render: with open(file_full_path, 'r', encoding='utf-8') as f: content = f.read() post = frontmatter.Frontmatter.read(content) # c = frontmatter.loads(content) # 버전 차이?
# 5) frontmatter없는 파일은 pass if 'attributes' not in post: # {'attributes': None, 'body': '', 'frontmatter': ''} # raise ValueError('해당파일에 frontmatter가 빠짐: ', file_full_path) print(f'🤣 frontmatter가 없는 파일 수정 요망: {file_full_path}') continue ## front용 path지정(백엔드 달리면 필요 없을 듯) # 15-1) path 속성이 있다면, 파일명이 아니라, [path].html로 상대 경로를 지정한다. if 'path' in post['attributes']: # 15-2) path는 중복이 아니여야 한다. if post['attributes']['path'] in post_paths: # raise ValueError(f'중복된 path가 있습니다: {post["path"]}') print(f'🤣 중복된 path를 가진 파일 : {file_full_path}') print(f'post_paths >> {post_paths}') continue # 15-3) 중복이 아닌 path는 True로 체크해서 추후 중복이 안되게 한다. post_paths[post['attributes']['path']] = True posts.append(post)```
datetime속성을 추가해야 역순이후 index처리 가능
-
date(string, 2025-02-03)을 datetime으로 바꾼 뒤,
date_parsed로서 시간비교하게 한다.- 이 때, 미래 날짜(오늘과 비교해서 크면) 건너띈다.
```python
15-3) 'date' 속성을 검사하여 있다면, 'date_parsed' 속성으로 str -> datetime으로 바꿔 넣어놓는다.
if 'date' in post['attributes']: # 'date': 2023-02-20 post['attributes']['date_parsed'] = post['attributes']['date'].strptime('%Y-%m-%d')
# 15-4) 근데, 발행날짜가 미래면, 무시하도록 한다. # 오늘 00시 발행법: datetime.datetime.combine(datetime.date.today(), datetime.datetime.min.time()) # >> datetime.datetime(2025, 3, 8, 0, 0) if post['date_parsed'] > datetime.datetime.combine(datetime.date.today(), datetime.datetime.min.time()): print(f'🤣 미래 날짜의 파일 : {file_full_path}') continue```
-
posts를 순회하며 html로 쓸 때, sorted()로 정렬한다.
```python env = jinja2.Environment(loader=jinja2.FileSystemLoader(TEMPLATE_DIR)) content_template = env.get_template('contents.html')
16) render하기 전, post를 date_parsed로 정렬. 속성 없을 수도 있으니, .get()으로 가져온다.
sorted( posts, key=lambda x: x['attributes'].get('date_parsed', datetime.datetime.min), reverse=True, ) ```
-
index처리를 위해서, enumerate로 순회하여, 총갯수 len(posts)와 i를 비교하여 next, prev post처리를 한다.
```python
render
for i, post in enumerate(posts): # 17-1) init prev/next prev_post = next_post = None # 아직 안끝났으면, next post객체를 넣어놓기 if i < len(posts) - 1: next_post = posts[i + 1] # 0번째가 아니면, prev post객체를 넣어놓기 if i > 0: prev_post = posts[i - 1] ```
prev, next post는 jinja이후 변수로 넘겨줘서 가능한 것
-
path를 속성으로 가지고 있으면, 해당path의 시작페이지 index.html로 간주하도록
'path': /blog/nested/post형식으로 카테고리 형식으로 사용하게 될 듯.
-
path를 직접 넣어준 post만 path +
/index.html로 주소를 바꿔주고, 처리해준다. -
path를 안넣어준 post에 대해서는, 직접 파일명으로 변경해줘야하는데, 이미 os.walk()를 지나간 상태라. os.walk()순회시 attributes에 넣어줘야할 것 같다.
python if 'path' in post['attributes']: #... else: # 15-4) path가 없으면, 파일명 .md ->.html 변경 기존 로직이 적용하는 file_full_path를 나중에 쓰기 위해 # file_full_path속성으로 저장해놓는다. post['attributes']['file_full_path'] = file_full_path -
이제 path가 있으면 path + /index.html 없으면 file_full_path를 outfut_dir 대체 및 html로 변경한 이름을 relative_path변수에 저장해놓는다